
Как работает стратегическая нейросеть
Date - 16.05.2017 / Author - admin / Category - AlphaGo, Без рубрики, интеллект, мультистратегияКороткий разбор принципа работы нейросети AlphaGo. Возможно, что по этому принципу будут построена универсальная стратегическая нейросеть, которая сможет решать прикладные задачи по сценированию, прогнозам и оценке эффективности проектов.
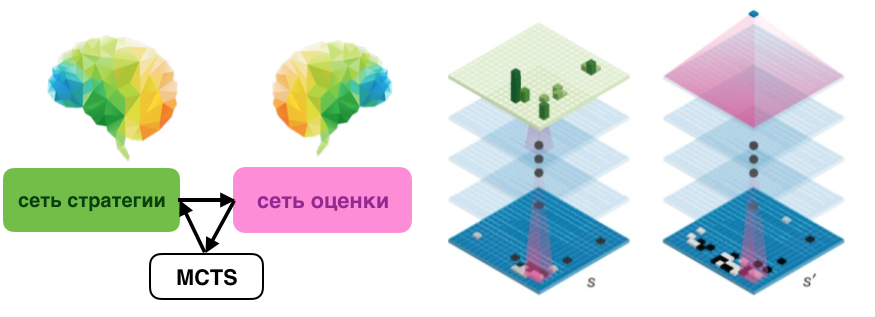
Инновацией Google было соединение нейросети стратегии, нейросети оценки и метода монте-карло для дерева поиска. Метод MCTS и раньше широко использовался в игровых программах Го и шахмат. AlphaGo в отличие от обычных программ, образно говоря, обладает двумя дополнительными «мозгами», которые выбирают очень хорошие ходы-кандидаты для глубокого расчета последующих вариантов игры.

Сравнение характеристик нейросети и чемпиона
Оценка мощности мозга в почти 900 000 процессоров взята из публикации IBM о планах создать полную симуляцию человеческого мозга, на которую по оценкам компании потребуется такое число вычислительной мощности.
Несмотря на значительно меньшую мощность, нейросеть AlphaGo показала себя очень хорошо. Человеку остается радоваться лишь впечатляющей энергоэффективности. AlphaGo не изобрела новых тактических решений, но показала иной взгляд на стратегию игры. То, что раньше было, скорее, чувством и отдельными проблесками гениев, сейчас можно описать как стратегию. И она очень необычная. По крайней мере, ее не найти в современных книгах по Го. Они обычно пестрят игровыми вариантами, но в них нет ни слова о принципах и стратегии. Зато о стратегии AlphaGo много говорится в «Искусстве войны» Сунь-цзы.
как принимают решение мастер и AlphaGo
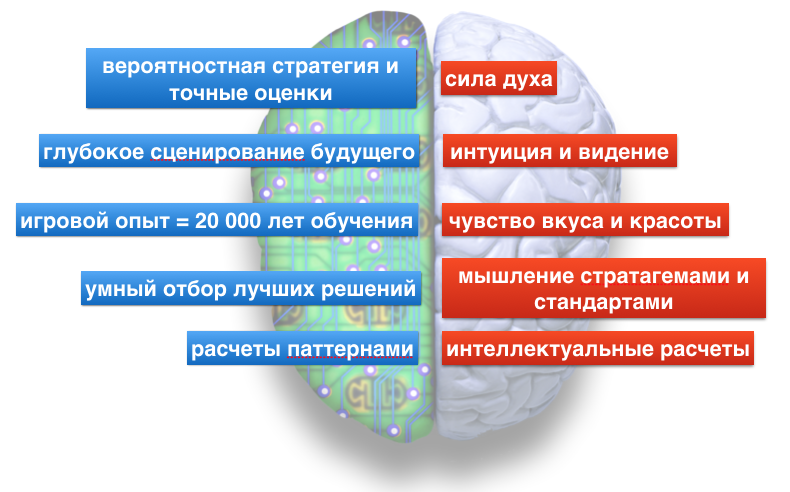
Принцип действия AlphaGo во многом похож на то, как играет человек. В отличие от нас, у нейросети нет духа, она не обладает вкусом или чувством прекрасного. И ее решения впечатляюще точны. Конечно, колоссальная фора — это скорость обучения. Сеть учится примерно в 12 000 быстрее человека и за все время своего обучения сыграла столько игр, сколько человек мог бы сыграть за 20 000 лет. Человечество практикуется в Го около 3 000 лет.
два мозга AlphaGo
Сеть стратегии является базовой сетью, с которой начинали обучение Го. По-настоящему она включает в себя две сети: сеть стратегии, обученную с подкреплением, и сеть быстрых прогнозов, которая училась по прецедентам и паттернам (30 миллионов позиций из любительских игр). Всего в ней 13 слоев, каждый из которых отвечает за ту или иную аналитику (например, подсчет дыханий, определение глаз и т.п.). Подобным образом — послойно — устроено зрение человека. Чтобы вы увидели кошку, мозг задействует около 10 слоев нейронов.
Создатели AlphaGo подошли к обучению стратегической сети с неожиданного угла. Число вариантов в Го астрономически велико. И если для шахмат создатели Deep Blue сумели построить функцию с 8 000 параметров, то в игре Го по разным подсчетам такая функция включала бы до миллиона параметров. Пока такие модели за гранью наших возможностей. Однако человеческий мозг легко справляется с подобными задачами.
И тогда программисты спросили себя: почему не научить нейросеть распознавать стратегические проблемы на доске Го так же, как мы учим нейросети распознавать изображения? Пусть сеть анализирует отдельные ходы, как часть стратегической картины в целом. За этим смелым решением стоит гипотеза, что все стратегические ситуации являются типовыми и их число ограничено. Кстати, из такой же гипотезы исходили создатели Книги Перемен в Древнем Китае, типируя жизненные ситуации. Им хватило 64 типов.
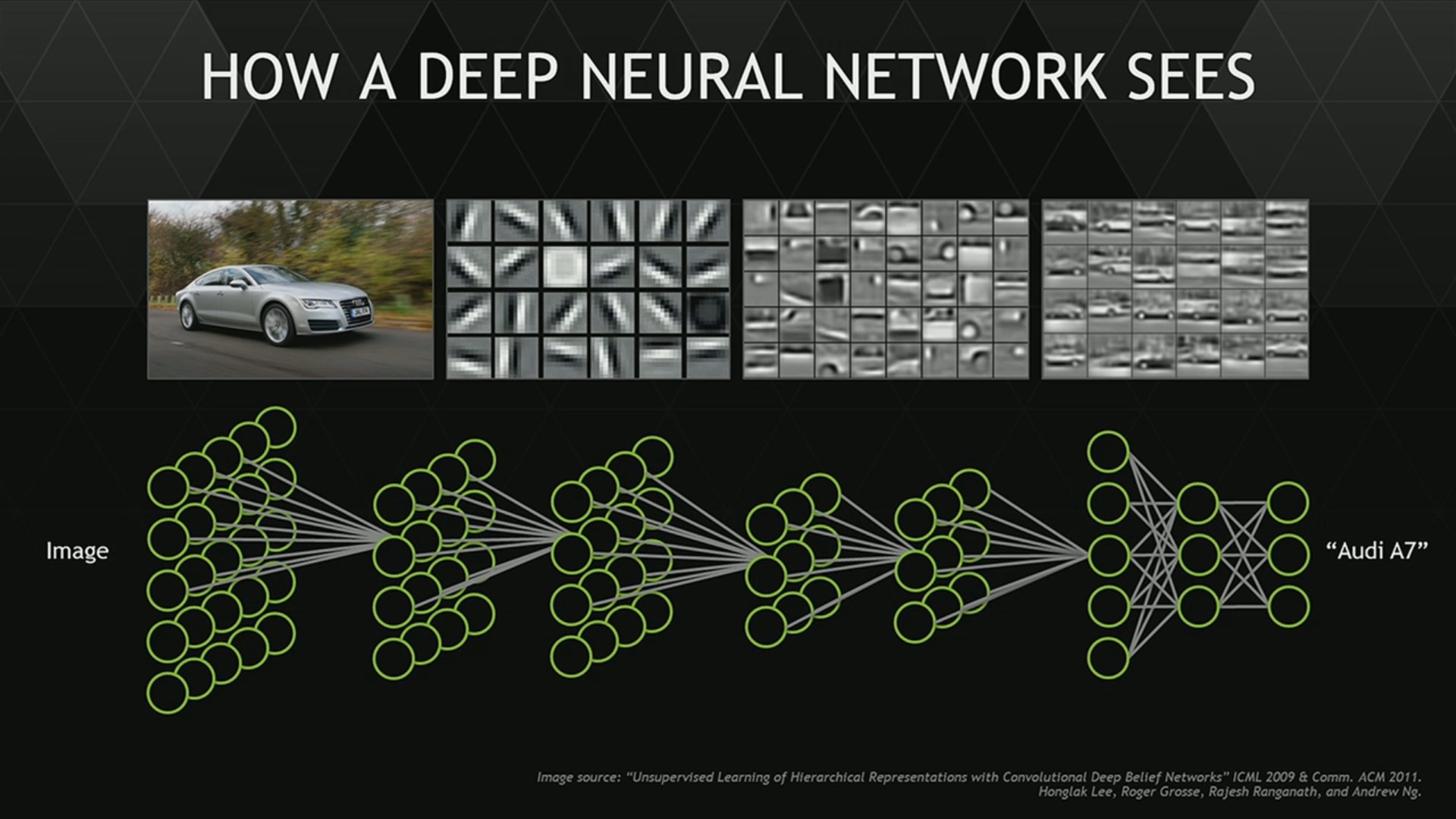
Как видит нейросеть. AlphaGo подобным образом распознает ключевые места в позиции для поиска лучших решений
Другими словами, у любой проблемы или стратегии есть лицо с «хвостом» и «усами». По крайней мере, для игры Го такой подход сработал. И нейросеть училась распознавать типы стратегий и проблем, рассматривая 29 миллионов позиций (последний миллион был тестовой выборкой для экзамена). Она научилась обобщать типы позиций, в которых нужно выживать и в которых, наоборот, нужно жертвовать, позиции атаки и позиции мирного дележа. AlphaGo созерцает расстановку камней, относя ее к одному из известных ей типов ситуаций и после этого ищет лучшее решение для нее.
Звучит заманчиво и даже немного невероятно. Напоминает врача, который сразу видит, что болит и где. Но именно таким позиционным зрением отличается мастер от новичка, он сразу видит, что происходит на доске, с первого взгляда. Ему не нужно рассчитывать сложные варианты, чтобы увидеть проблему и определить ее тип. Вот почему Google обучал игре Го нейросеть для распознавания изображений. Го учит видеть!
Сеть стратегии отвечает за разработку вероятностной стратегии и быстрые прогнозы по базе прецедентов и базе стандартных игровых паттернов. Прогнозы необходимы для оценочной сети, которая решает иную задачу.
Сеть оценки должна определять ценностный вклад каждого хода в победу. Она рассчитывает шансы на победу и проводит интеллектуальный анализ позиции, собирая самую разную информацию с точки зрения качества решений. Оценочная сеть тренировалась оценивать позиции по своей уникальной базе из 30 миллионов, которую для нее составили две нейросети, игравшие сами с собой. То есть она училась уже не на человеческих прецедентах, а на играх машины самой с собой.
Эта сеть способна выбрать несколько кандидатов с высокими шансами на победу, базируясь на наработанном экспертном опыте. И здесь ей на помощь приходит сеть быстрых прогнозов, которая на большой скорости моделирует множество игр от каждого кандидата и до подсчета очков. Набирая статистику, сеть прогнозов позволяет уточнить вероятность победы у рассматриваемых решений.

«Закипел!» — Фан Хуэй проигрывает AlphaGo
Все мастера отмечают удивительную точность оценки позиции AlphaGo. Современный профессиональный игрок Го не способен так точно взвесить ценность своих постановок. И потому даже чемпионы ошибаются, выбирая из нескольких хороших решений не самое лучшее.
Между стратегической сетью и сетью оценки могут возникать конфликты. Стратегическая сеть выбирает лучшее решение с точки зрения локальной позиции, но сеть оценки может поставить ему низкий приоритет, так как ее аналитика основана на глобальной оценке позиции и анализе вклада этого решения в победу. Для решения конфликтов между сетями используется алгоритм MCTS (поиск по дереву монте-карло). Он проводит глубокое сценирование всех спорных кандидатов и позволяет выбрать самого лучшего.
Горизонт эффективного планирования у MCTS примерно в 100 постановок. Есть пример в опубликованной игре между двумя нейросетями, где одна из них боролась в заведомо проигрышной позиции, но поражение стало очевидным лишь после 120-й постановки в борьбе. Человек обычно планирует не более чем на 30 шагов. Ведь на каждом шаге фактор ветвления 250 вариантов. Допустим, мы рассматриваем только ключевые, но все равно вариантов там сотни, и в уме нужно держать около 50 реальных сценариев.
Один из примеров конфликта между сетями — знаменитый ход № 37 из второй игры между Ли Седолем и AlphaGo. Стратегическая сеть оценила вероятность этого решения в 0,0001. То есть, так ее играть не учили. А вот сеть оценки отдала ему максимальный приоритет. И глубокое сценирование MCTS показало, что этот камень действительно хорош. Кстати, корейский чемпион поступил так же, как и стратегическая сеть — недооценил эффективность этого решения, которое начинало работать в полную силу лишь через 50 постановок. Просчитать такое никакому мастеру не под силу. Это можно только почувствовать или увидеть.
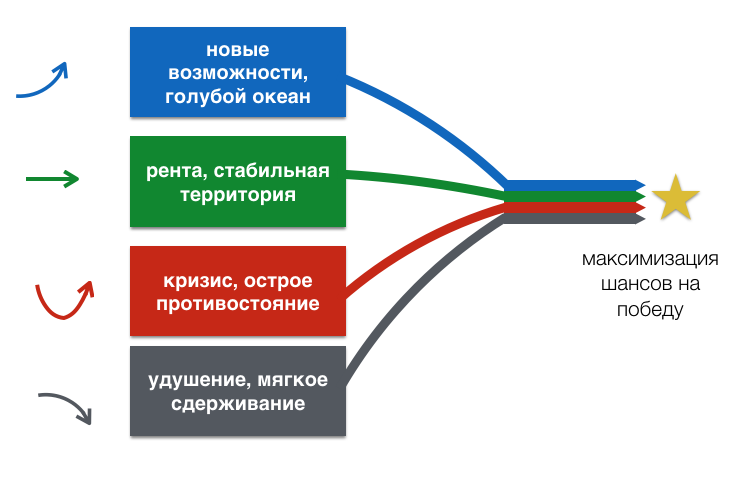
Об этом не пишут в книгах о Го — базовые стратегические сценарии AlphaGo. Результаты исследований Русской Школы Го и Стратегии
Что действительно удивляет, так это особая стратегия AlphaGo. Китайцы называют ее гибкой и отмечают легкость, с которой нейросеть переключается между казалось бы противоречивыми сценариями игры. Дело в том, что она рассматривает эти сценарии как стратегическое миаи. Только гениальные мастера играли в таком ключе.
Каждый камень, который ставит AlphaGo, работает сразу на несколько сценариев одновременно. Конечно, найти такой ход-мультипликатор не всегда возможно. Мультипликативный эффект позволяет соблюдать один из принципов Го — не определяйся без необходимости, но при этом двигаться к победе. Главное, не попасть в ловушку неопределенности и не наставить пустых камней, которые неопределенные настолько, что ничего не делают. Поэтому человек обычно играет в одном-двух сценариях одновременно. А нейросеть способна играть сразу в четырех, переходя из одного в другой, где шансы на победу выше. И это дает ей устрашающее интеллектуальное преимущество.
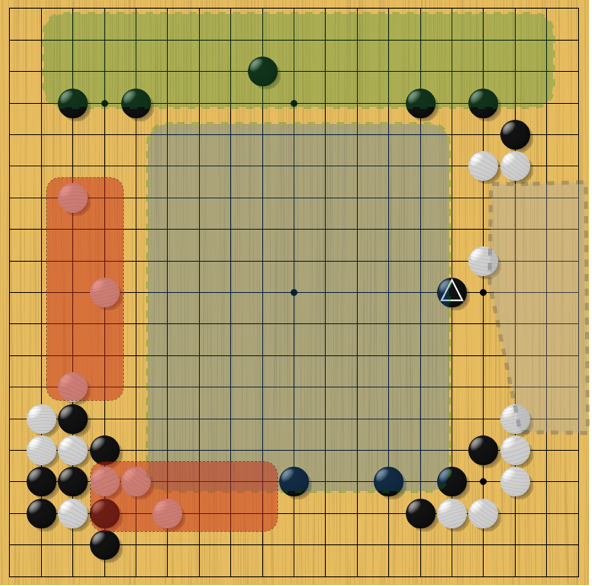
Четыре сценария хода № 37 (отмеченный треугольником черный камень) Сценарий в центре будет реализован через 50 постановок
Наиболее близкий аналог стратегии AlphaGo — это стратегия реальных опционов. За формулу их оценки американские экономисты Ф. Блэк и М. Шоулз получили нобелевскую премию в 1973 году. Реальные опционы — это твои возможности. Обычно в Го борются за два базовых актива — владение и влияние. AlphaGo открыла новый тип актива, который в принципе был известен в Го за столетия до нейросетей. Это стратегия сэнтэ или стратегия темпов. Темп — это военный термин, введенный военным теоретиком М. Галактионовым.
В современном Го под сэнтэ понимают только тактику, а стратегическое измерение упускают из виду. Но так было не всегда. Если взглянуть на игры Досаку (18 век) или Дзёвы (19) век, то их знаменитая стратегия амаси — стратегического сдерживания и незаметного господства — это максимизация возможностей и темпов в то время, пока недальновидный соперник борется за территорию или влияние, или съедает камни. Нейросеть научилась этой стратегии сама.
автор: М. Емельянов.
Comments are closed.