
Что строит AlphaGo?
Date - 11.03.2016 / Author - admin / Category - AlphaGo, Без рубрики, интеллектВ нашей школе есть формула «ставь, правь, строй». Она объясняет порядок стратегии в игре. Хорошая формула носит универсальный характер. И я полагаю, что наша формула действительно хороша. Сейчас становится ясной стратегия DeepMind. Мы видим, на что они сделали ставку, Но что намерены изменить и исправить, и что они строят? И это интересный вопрос!
Сейчас, после двух поражений Ли Седоля, мы еще не можем делать окончательный вывод о победе искусственного интеллекта над чемпионом мира. Бог любит троицу, даже если это Го-бог. Кстати, мастер Го Сэйгэн говорил как-то, что сыграл бы с таким сверхразумом на двух или трех камнях форы. Плюс ситуации еще и в том, что в Го нет одного чемпиона мира. AlphaGo придется еще сразиться с чемпионом Китая и чемпионом Японии, чтобы закрепить успех. Но всё это не важно. Наше внимание приковано к матчу, мы следим за камнями, переживаем за Ли Седоля, потому что он не заслужил такого бремени. Но он мастер и возможно, что этот матч изменит его, открыв ему то, что раньше было недоступно. Главное как всегда происходит на периферии внимания: не там где камни, а там, что эти камни окружают. И в эту terra incognita любопытно заглянуть.
Небольшой исторический экскурс поможет нам это сделать. Ведь искусственный интеллект создается не впервые. Более того, мы окружены его формами, некоторые из которых очень стары.

Гадательные кости с предсказаниями, эпоха Шан
Возникновение Го в Древнем Китае окутано мраком. Историки связывают его с возвышением династии Чжоу. Есть даже имя потенциального создателя игры: мифический мудрец-сановник Цзы Ци. Его персона интересна тем, что он был первым министром у последнего императора династии Шан. Но тот, не внял его советам. И тогда по легенде Цзы Ци предложил свои услуги клану Чжоу, возвысив новую династию. Этому мудрецу приписывают изобретение триграмм и Го, которые стали новым методом описания реальности: в первую очередь гадания и предсказания будущего. Чтобы было понятно, о чем идет речь, процитирую Демиса Хассабиса:
«Рак, изменение климата, энергетика, геномика, макроэкономика, финансовые системы, физика. Многие из систем, которые мы хотели бы освоить, становятся слишком сложными. Информационная перегрузка в них такова, что даже для самых умных людей очень трудно справиться с этими проблемами в течение своей жизни. Как пройти через эту лавину данных, чтобы найти правильные идеи? Один из способов мышления AGI это процесс, который будет автоматически конвертировать неструктурированные данные в полезные знания. То, что мы создаем – это алгоритм мета-решения любой проблемы».
Примерно таким содержанием были наполнены речи министра, обращенные к представителю старого мира шаманов, род которых и был династией правителей Шан. Объявление войны и мира, время начала посевной и сбора урожая, погода на зиму и возможные наводнения весной — ответы на эти вопросы находили с помощью гадания по трещинам обожженных костей. Цзы Ци предложил заменить шаманскую архаику инновационным изобретением. Он придумал новый язык и даже сделал свой «гаджет», с помощью которого можно было бы искать ответы, не рассматривая кости, а на «экране» его устройства под названием zhangfang. Суть заложенных в него алгоритмов иллюстрируют следующие рисунки:
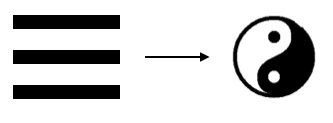

Вы понимаете, что здесь изображено? Если нет, то войдете в положение последнего императора Шан, который отправил своего первого министра отдохнуть в отдаленную провинцию на десять лет. Слева на рисунке показан символ «ци». Это краеугольное понятие древнекитайской философии, согласно которой «единица рождает двойку, двойка рождает тройку, тройка рождает 10 000 вещей». «Ци» может быть раскрыто в динамическом виде как диаграмма инь-ян. Справа показано, как с помощью бинарного кода прямой и прерывистой черт образуются восемь триграмм. Они соотносятся с восемью сторонами света и, условно говоря, моделируют любые явления, которые могут произойти. Далее из них образуется круг из 64 гексаграмм, составляющих Книгу перемен. Для сравнения посмотрите на схему из доклада DeepMind об обучении с подкреплением для нейросетей.
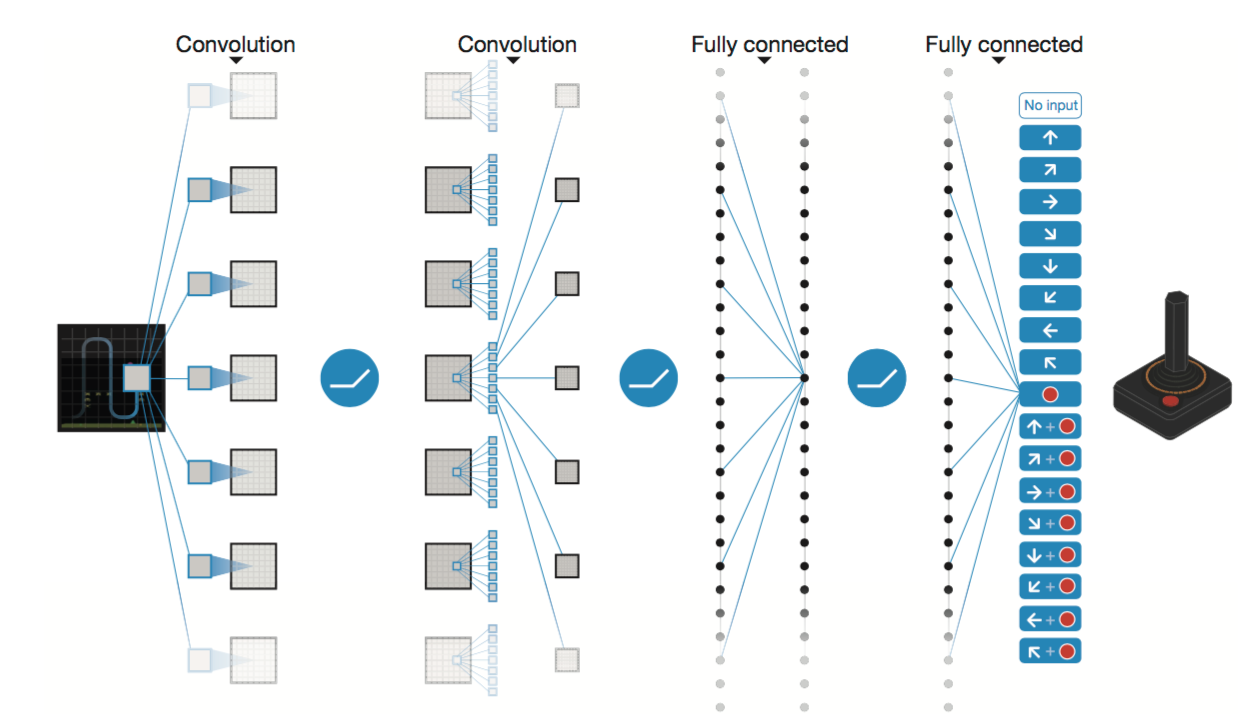
Эта схема также непонятна неискушенному читателю, как и предыдущие рисунки. Но главное, что она работает, что и демонстрирует сейчас AlphaGo в Сеуле. Древнекитайский мудрец построил первый в истории Китая (не берусь говорить о мировой истории) алгоритм искусственного интеллекта, предложив заменить шаманство технологией, если уместно так называть его изобретение. Но заметим вот что. Разработчики AlphaGo не могут нам объяснить, как сеть принимает решения и делает свой выбор. Они не управляют ее выбором, дав ей лишь алгоритмы самообучения. Также мы не можем понять, как работают восемь триграмм и Книга перемен. Мы можем лишь проверять эту интеллектуальную систему на практике. А она интеллектуальна, так как содержит в себе лишь бинарные знаки и отношения между ними.
Считается что игра Го выросла из «гаджета», работающего на древнем аналоге AGI, который играл роль виртуального советника для правителя. DeepMind сейчас разрабатывает на базе AlphaGo своего виртуального помощника для смартфонов. Нейросеть ляжет в основу искусственного интеллекта и для системы здравоохранения Великобритании. Получив такой «гаджет» древнему правителю не надо было жечь кости и рассматривать трещины. Он мог легким движением руки получить комбинацию символов, интерпретация которых давала ответы на поставленные вопросы. До наших дней не сохранилось ни одного zhangfang’a. Можете набить в поиске «китайский компас» — это поздний упрощенный прототип этой древней штуки.
Доска для Го использовалась и как календарь с 24 сезонами, и для гадательных предсказаний, и как зеркало психического состояния вопрошающего, и как агрегатор стратегических паттернов и логических отношений. Китайцы на доске Го объясняли даже бином Ньютона.
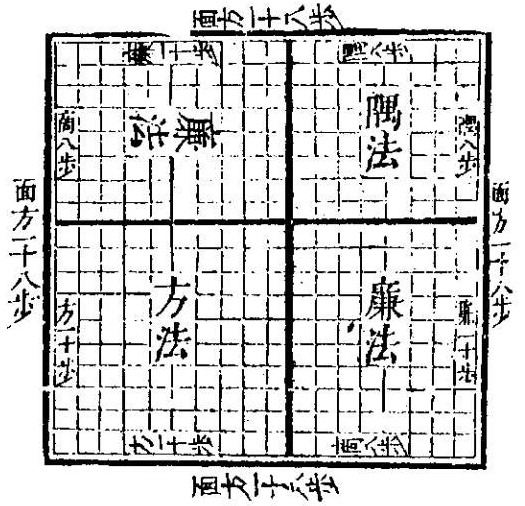
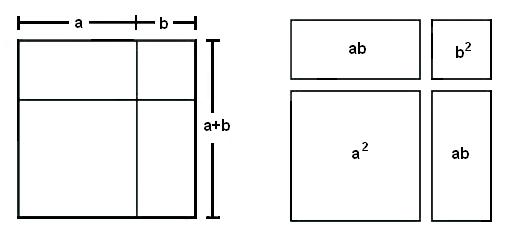
Бином Ньютона объяснен на доске Го с помощью отношения площадей. Источник: «Полная коллекция вычислительных методов» или Suanfa tangzong (1592). Автор Чэн Давэй.
Эта «закрывающая технология» попала в руки к вождю племени Чжоу, знаменитому У Вану, который свергнул династию Шан и установил свою, правившую почти 1000 лет. Цзы Ци стал его первым министром и советником.
Для любителей Го это будет звучать странно, но в те далекие времена в Го вряд ли играли так, как это делаем мы. Скорее, исследовали насущные проблемы, выуживали заложенные в модель знания. Да, гадали о будущем, также как ученые XXI века будут запрашивать у AlphaGo прогнозы катастроф или рассчитывать с ее помощью вероятность обитаемости той или иной планеты. Сам дизайн игры был футуристичен. Для правителей древности было немыслимо разбираться со стратегией войны и мира на доске с помощью камней, а не вопрошать у богов на ритуальных костях. Также как сейчас для нас немыслимо поручать искусственному интеллекту воспитание детей или разрабатывать политику государства.
Мы пока не готовы признать способность системы из 280 GPU и 1920 CPU имитировать интуицию и мышление, побеждая мастеров высшего класса. Ведь Го игра для человека, а какая может быть интуиция у машины? Правда в том, что само Го — это машина. Это модель ratio в чистом виде, которая вытравляла шаманское сознание из голов правителей и окружавших их людей, демонстрируя невероятную в те время идею: надо думать, рассчитывать и моделировать, а не получать готовый ответ от шамана, который в трансе общается с богами. Похоже, что мы сейчас переживаем столкновение нашего шаманского сознания с новым типом машины искусственного интеллекта.
Миссия DeepMind звучит амбициозно и характеризует планы компании: 1. Solve intelligence. 2. Use it to solve everything else (Создать разум. Использовать его для решения любых проблем). AlphaGo — это первый шаг на пути создания такого сверхразума. Сейчас нейросеть состоит из двух сетей: политики, отвечающей за планирование и стратегию, и ценности, которая позволяет оценивать эффективность. Следующий шаг — это подключение функции памяти. У DeepMind есть дорожная карта шагов, которые следует пройти по этому пути. Я не могу себе представить, как сеть будет играть, когда она начнет накапливать опыт не только в сетях политики и ценности, но и в виде прямого запоминания, если и сейчас она действует практически безупречно.
Демис Хассабис относит AlphaGo к классу AGI, то есть неспециализированному искусственному интеллекту. По его определению general — «same system can operate across a wide range of tasks» (одна и даже система может оперировать с широким классом задач). В этом отличие AlphaGo от суперкомпьютеров, победивших человека в шахматах и других играх. AlphaGo запрограммирована только на то, чтобы очень хорошо учиться. Обучение с подкреплением (reinforcement learning) построено по простой схеме. Но за ней стоят «удивительно интересные алгоритмы». Что это за алгоритмы, мы скоро узнаем, так как DeepMind обещает открыть доступ к своим разработкам.
Рисунок на основе схемы из лекции Демиса Хассабиса
Я строю обучение Го по похожей схеме, только из трех элементов: осмотр, понимание, действие. Особенность нейросети, которая позволяет ей побеждать азиатских профессионалов с неожиданной легкостью в том, что она действительно повторяет в той или иной мере мыслительный процесс. Но я не уверен, что этот процесс лежит во главе угла у восточных профессионалов. Одна китайская профессионалка так описала свой способ игры: я выбираю стандартный паттерн из набора вариантов и следую ему, ничего не выдумывая (попробую найти точную цитату). Смысл цитаты заключался в том, что для нее главным является не творчество, а удачно подобранные друг к другу игровые шаблоны. Как становится ясно из объяснений разработчиков, AlphaGo действует принципиально иначе. У нее нет базы стандартных схем. Сеть опирается на натренированные оценки эффективных решений и каждый раз ищет решение с помощью заложенных алгоритмов Монте-Карло. Иногда ошибается, как в самом конце второй игры с Ли Седолем (постановка 167). Другое дело, что чемпион не решился воспользоваться этой ошибкой. Человек, в отличие от программы, физически устает и нервничает.
Какова будет правящая и строящая постановки DeepMind, говоря языком игры Го? Корреспондент The Verge задал такой вопрос главе компании: «AlphaGo обучалась на тысячах игровых паттернов Го. Как она может быть применима, например, к смартфонам, где вариативность входящей информации намного больше?» Демис Хассабис сказал то, что я, как и многие другие, хотели от него услышать:
«Да, есть куча информации об этом, по которой вы и делаете такой вывод. На самом деле AlphaGo — это алгоритм. И мы собираемся попробовать в ближайшие несколько месяцев отказаться от управляемого обучения сети на начальном этапе. Пусть она просто самостоятельно играет, начиная учиться буквально с нуля. Это займет больше времени, поскольку ей придется действовать методом проб и ошибок. А когда играешь на основе случайного выбора, то тренировка занимает больше времени. Нам потребуется, может быть, несколько месяцев. Но мы считаем возможным дойти до чистого обучения. Мы могли бы это сделать и раньше, но такой подход не сделал бы программу сильнее. Хотя в случае с играми Atari у сети не было подсказок от людей. Она начинала играть случайным образом. В Го, в отличие от компьютерных игр Atari, намного сложнее понять, ведут ли твои действия к победе или нет, даже через сто шагов… Цель DeepMind не в том, чтобы побеждать во всех играх ради веселья. Игры полезны для тренировки сети и тестирования алгоритмов, насколько они хороши. Игры позволяют делать это очень эффективно. В конечном счете мы хотим использовать AlphaGo для решения больших мировых проблем».
Машина AlphaGo учится рационально «по-человечески» мыслить на том же инструменте, что и человек древности — с помощью Го и других игр. Facebook создает свой AGI, обучая его читать и понимать тексты. Похоже, что соревнование между буквенной и иероглифической цивилизациями только в самом начале. И нас ждет много сюрпризов.
Есть и другое измерение происходящего. Победа AlphaGo над чемпионом Го Кореи — это удар в сердце культурного кода Азии. Ведь они сознавали превосходство Го над шахматами, свое безусловное превосходство в Го над всем миром и считали, что превосходят запад в разработках искусственного интеллекта. Google бросил вызов Востоку, в первую очередь Китаю, правда, пока не победив китайского чемпиона в Го. Но AlphaGo готовится сделать это, показывая превосходство европейской технологической науки над восточной моделью развития человека. И это тот вызов, на который и надо искать ответ, а не выставлять под каток очередного чемпиона. Что можно противопоставить эволюции машин? Способны ли мы также эффективно развивать человека? DeepMind показывает нам, как надо использовать Го, и у них есть чему поучиться.
автор: Михаил Емельянов.
Comments are closed.