
AlphaGo победил чемпиона Европы в Го. Что дальше?
Date - 30.01.2016 / Author - admin / Category - AlphaGo, Без рубрики, интеллект, стратегияХочу поздравить команду Google c первой реальной победой. Они действительно создали очень сильную игровую программу. Поначалу я скептически отнесся к новости, но изучив записи игр, изменил свое мнение. Также я впечатлен медийной волной, которую им удалось поднять. Пожалуй, теперь все знают о существовании загадочной китайской игры Го, в которую компьютер наконец сумел одолеть человека. В этой статье я расскажу, что же все-таки случилось и чем это всем нам грозит: как любителям игры Го, так и всему человечеству.

Аватар для Го-программы AlphaGo? Я думаю, что Google выберет медвежонка или ученого.
Во-первых, речь не идет о победе над человеком. Пока это дело будущего. Мой прогноз 5-7 лет. Возможно, соревнование двух гигантов Google и Facebook за первенство в разгроме сильнейших чемпионов Го планеты добавит скорости этому процессу. Факты таковы. Программа Alpha Go, в которой реализован искусственный интеллект (artificial intelligence, AI), победила в матче с чемпионом Европы 2015 года со счетом 5-0. Fan Hui (Фан Хуэй) — китайский профессиональный игрок 2-го дана, который много лет живет во Франции. Я видел его на разных турнирах, как в Лондоне, так и в Париже. Очень приятный и улыбчивый человек. Обычно он выступает с лекциями и разборами. Также он тренирует детскую сборную Франции. Он трижды становился чемпионом Европы. Это, безусловно, серьезное достижение. Наш русский профессионал Александр Динерштейн становился чемпионом Европы 7 раз, так что нам тоже есть чем гордиться.
Фан, конечно, достаточно силен и входит в десятку сильнейших игроков Европы. Но все же он далек от звания чемпиона мира, как его окрестили некоторые заголовки. Так что мы проиграли битву, но не войну. Кстати, игр было 10, пять из которых не пошли в зачет и не были опубликованы. Также меня удивил выбранный им регламент времени — по часу человеку и программе, плюс небольшое дополнительное время. Это не много. Серьезные чемпионские поединки предполагают 4-6 часов каждому. Вот как он сам описал свои впечатления от игр журналу Nature:

Fan Hui играет в Го с AlphaGo
«В Китае Го — это не просто игра. Это зеркало жизни. Мы говорим, что причины твоих неудач в игре, возможно, те же, что и в жизни. Пережить поражение было очень тяжело. До первой игры с AlphaGo, я думал, что смогу победить. После первого поражения я изменил свою стратегию и больше сражался, но я проиграл. Проблема в том, что человек иногда совершает большие ошибки, потому что он человек. Иногда мы устали, иногда слишком хотим победить, это давит на нас. В случае с программой всё иначе. Она очень стабильна и сильна. Как будто это стена. Игры с ней удивительно отличались от поединков с людьми. Я знаю, что AlphaGo — это компьютер. Но если бы мне никто не сказал об этом, то я бы подумал, что мой противник немного странный, но что это очень сильный реальный игрок.
Конечно, проиграв, я не был счастлив, но все профессионалы проигрывают множество игр. Я проиграл, поэтому я изучу свои ошибки и возможно, смогу изменить свою игру. Я думаю, что это хороший опыт».
Матч прошел еще в прошлой осенью. Но Google решил объявить о его результатах сразу после того, как Марк Цукерберг анонсировал большие успехи своей команды в разработке собственной играющей программы. Ролик о ней можно найти на Facebоok.
Следующий шаг Google — матч с действительно серьезным соперником — Ли Седолем. Это выдающийся корейский профессионал 9-го дана, обладатель нескольких титулов и долгое время считавшийся мастером № 1 в мире. В Го, в отличие от шахмат и привычной нам спортивной системы, нет титула чемпиона мира. Точнее, его может получить только игрок-любитель. Важно помнить, что любительские ранги поднимаются с 1-го по 7-й дан. Большинство любителей и мастеров игры в Европе — это обладатели любительских рангов. Чтобы получить 1-й профессиональный дан (который выше 7-го любительского), необходимо стать членом профессиональной ассоциации. Для этого нужно пройти обучение и сдать «экзамен» в виде квалификационного турнира по очень жесткой схеме (например, 100 претендентов и 3 победителя на выходе). Профессионалы не борются между собой за звание чемпиона, а подобно теннисистам и боксерам разыгрывают титулы. Чем больше титулов в течение года удается завоевать мастеру, тем выше его признание и статус. Ли Седоль, полагаю, входит в пятерку сильнейших профессиональных игроков на планете. И анонсированный матч уже вызвал ажиотаж. В случае победы Google заплатит корейскому профессионалу 1 миллион долларов. В случае победы AlphaGo деньги уйдут на благотворительность. Ли Седоль смотрит на свои шансы с оптимизмом:

Ли Седоль в матче против одного из сильнейших мастеров Китая Гу Ли.
«В этот раз я, конечно, выиграю со счетом 4-1 или 5-0, но я уверен, что через 2-3 года создатели AlphaGo захотят взять у меня реванш. Вот тогда мне будет действительно непросто победить».
Но Google также рассчитывает на победу. Один из программистов компании-разработчика DeepMind Дэвид Сильвер сказал журналистам:
«Я не ставил денег на победу AlphaGo, но я думаю, у нас неплохая репутация, чтобы сделать такие ставки. Так что давайте просто скажем, что мы будем очень разочарованы, если проиграем матч в марте. Но вы знаете, всё возможно. У людей, несомненно, есть много трюков в рукаве, против которых мы не тренировали нашу программу».
Эксперты, в основном это мастера из Китая и Кореи, сходятся на том, что хоть программа и феноменально сильна, она не играет на уровне 9 проф. дана. Ке Чжие, китайский вундеркинд и 9 проф. дан так охарактеризовал свое впечатление от просмотренных игр между Fan Hui и AlphaGo:
«AlphaGo напоминает игру подростка, который с раннего детства занимался игрой Го и сейчас почти достиг уровня 1 профессионального дана. Он еще не профессионал, но очень близок к этому. Его игра сбалансирована и хороша во всех стадиях партии (в фусэки, тюрбан и ёсэ). Конечно, мы не увидим слабости AlphaGo всего лишь по пяти партиям, в том числе потому, что оппонент играл столь плохо» (смеется).
Как видим, человек пока настроен решительно и уверен в себе. Коротко расскажу, что за революцию удалось совершить разработчикам Google. Пока мы не всё понимаем в том, что сделано, тем более, что основную информацию DeepMind в открытый доступ еще не предоставил. Но обещает это сделать в скором будущем.
Во-первых, инновация Google состоит в сочетании так называемых value networks (сети ценности) и policy networks (сети политики). Мне не удалось найти корректные переводы этих типов нейросетей на русский. Value networks отвечает за оценку позиции. Policy networks отвечает за выбор лучшего хода. Одной из проблем программирования игры Го являлась сложность оценки позиции. В отличие от шахмат, в Го ценность одного и того же камня может значительно меняться в ходе игры. Эти сети обучались по инновационной методике, которая сочетала изучение партий сильных игроков, и самообучение путем проведения тысяч игр между нейронными сетями. Еще одна инновация разработчиков Google — новый алгоритм поиска решений, который сочетает метод Монте-Карло с value и policy сетями. В результате AlphaGo обыгрывает все существующие Го-программы (в том числе Crazy Stone и Zen) с результатом от 80% до 99%. Третье, и на мой взгляд, самое важное: разработчики Google создали свой уникальный алгоритм самообучения нейросети. Сеть способна учиться на своих ошибках и делает это хорошо. Это изобретение выходит далеко за рамки игры Го.
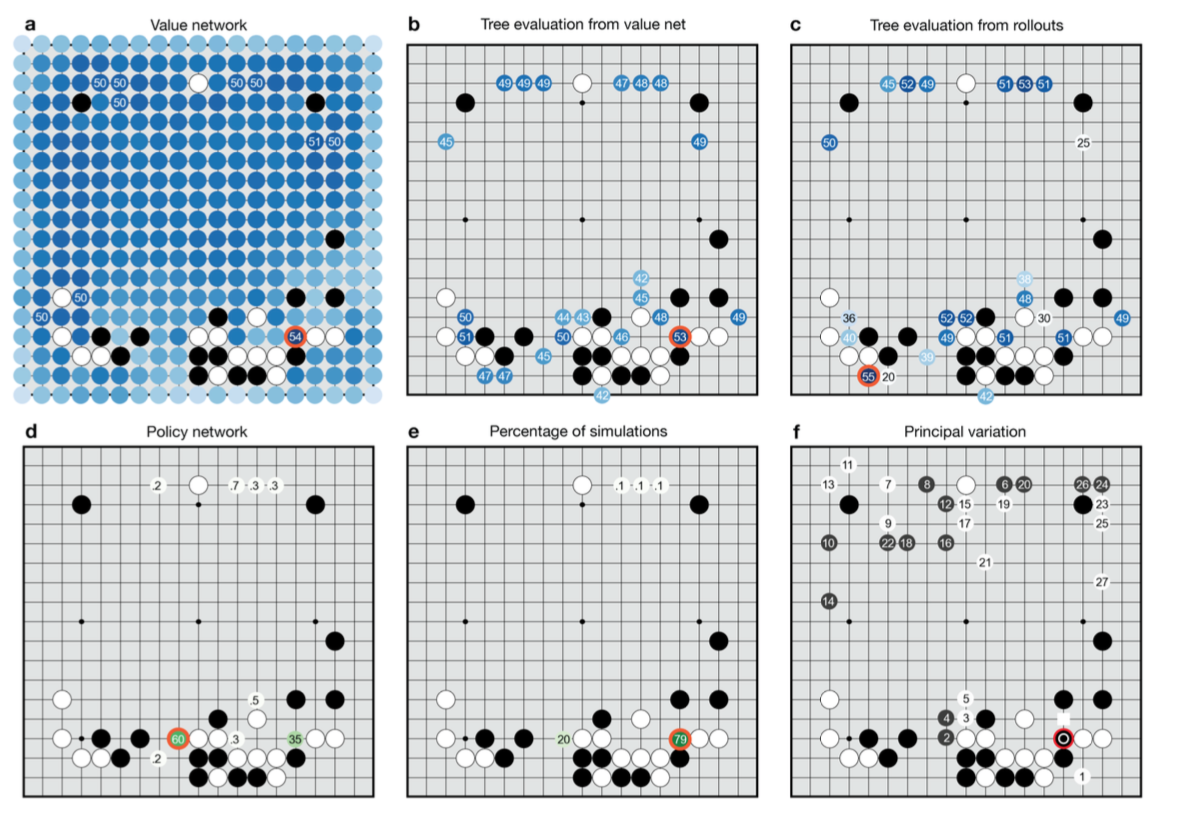
Пример работы нейронных сетей AlphaGo из отчета DeepMind
Возможно, что мое описание процесса обучения нейросети не полное, но я понял это следующим образом. Сначала разработчики тренировали нейронную сеть SL Policy Network на 30 миллионах позиций из партий игроков 6-9 дана с сервера KGS. Сеть получала позицию и угадывала вероятную постановку, которая будет следующим ходом. Сети давалась дополнительная информация, например, сколько у камня будет дыханий, сколько этим ходом будет захвачено камней, будет ли работать облава (лестница). В итоге сеть стала угадывать верное продолжение игры в 57% случаев и в 55% случаев, когда у нее была только конечная позиция с историей игры с самого начала. То есть, дополнительная информация ей оказалась и не нужна. Обучающим алгоритмом был «стохастический градиент восхождения» (stochastic gradient ascent).
Вот как описывает процедуру обучения geektimes.ru: «Нейросети натренировывали в нескольких стадиях машинного обучения. Сначала проводилось контролируемое обучение сети политики прямо с помощью ходов игроков-людей. Другая сеть политики подвергалась обучению с подкреплением. Вторая играла с первой и оптимизировала её, чтобы политика сдвигалась к выигрышу, а не просто предсказаниям ходов. Наконец, проводилось обучение с подкреплением сети ценности, которая предсказывает победителя игр, в которые играют сети политики. Конечный результат — это AlphaGo, комбинация метода Монте-Карло и сетей политики и ценности».
Итак, у нас есть нейросеть, которая угадывает решения игроков уровня дан с KGS. Но нам нужна сеть, которая будет угадывать лучшие решения. Тогда заставим такую сеть играть в Го саму с собой. В ходе тренировки она провела тысячи поединков, используя алгоритм самообучения (каков он, пока не известно) для корректировки ценности победных решений. Важная идея в том, что после изменения веса какого-то решения, сеть создавала нового «бота», чтобы каждый раз играть со случайным противником внутри себя. Это позволяло избежать «привыкания» сети побеждать типового соперника, вместо того, чтобы постоянно становиться сильнее. В результате натренированная сеть побеждала свою начальную версию (обученную по базе позиций KGS) в 80% случаев и обыгрывала Го-программу pachi в 85% случаях, не обращаясь ни к какой базе данных. То есть, эта сеть действительно натренировалась хорошо играть. Я сам не играл с pachi. Это Го-бот, который играет на сервере KGS, где имеет рейтинг 4 любительский дан, тренируясь на живых людях.
В итоге оказалось, что обученная на поединках сеть эффективнее той, что только пользуется базой позиций KGS. Авторы AlphaGo полагают, что это связано со слишком большой вариативностью действий, из которых сеть не может выбрать лучшее. Открыт вопрос, что получилось бы, если сеть сразу начала играть сама с собой по алгоритму самообучения, без предварительного изучения базы человеческих игр. Поднялась бы она на достигнутый уровень игры или так бы и играла на уровне начинающего? Я бы попробовал именно такой алгоритм обучения, либо соединил его с обучениям базовым принципам и стратегиям Го, но не знакомил бы программу с человеческим опытом в виде партий.

Разбираем 5-ю игру матча на Клубе Го и стратегии с Е. Островским. Часть автора статьи справа на переднем плане
По тому, что озвучено на сегодняшний день, можно сказать, что у человека появился сильный противник в игре Го — нейронная сеть, прошедшая ультратренировку. Вряд ли найдется мегамозг, который бы смог эффективно переварить такую базу знаний, как 30 миллионов позиций. Но интересно то, как устроен алгоритм самообучения. Похоже, что он отличается от того способа, которым мы учимся играть в Го. Самое любопытное для меня в том, закладывали ли программисты в этот алгоритм какие-то основополагающие принципы, или же они смогли построить его исключительно на математике. Если верно последнее, то в пору переосмыслять, что вообще такое мышление и интеллект, так как AlphaGo показала в некоторых ситуациях игру такого уровня, который человек может достичь только с помощью интуиции. Быть может, интуиция — это встроенный природой в человека стохастический алгоритм? И тогда в истории о том, что в конкурсе на женскую логику победил генератор случайных значений, появляется новый смысл.
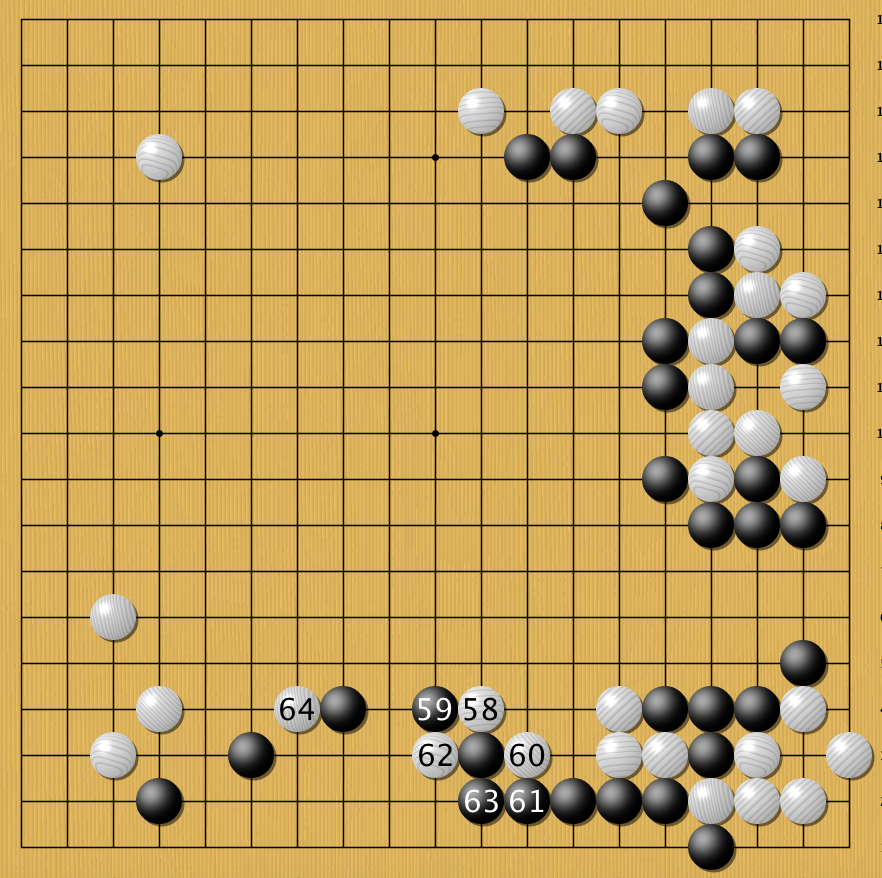
Блестящая комбинация решений AlphaGo за белых удивила многих экспертов. Постановки 58-64 человек сделает на интуиции. Просчитать их практически невозможно.
Что же нас ждет в будущем? Я вижу следующую картину. Два аватара от Google и Facebook играют в Го друг с другом, наподобие легендарных бессмертных в заповедной роще. Толпы туристов приходят посмотреть на это чудо. По древней китайской классификации мастерства третья сверху ступень (пин) называется «полная ясность». Это такой уровень игры, когда ты принимаешь решения, практически не считая варианты. Го Сэйгэн, пожалуй, сильнейший мастер XX века, говорил, что по его ощущениям он бы выиграл у «Го-бога» взяв два или три камня форы. Он полагал, что почти дошел до предела совершенства в понимании игры Го. Судя по всему, нейронная сеть скоро дойдет до этого же уровня.
Следующая ступень — «сидеть в просветлении» — указывает на предельные для человека состояния, которые определяются не ratio и логикой, а его сознанием и подсознанием в целом. Высшая ступень мастерства так и называется «сверх человека». Китайцы полагали, что предел человеческих способностей все-таки есть, но играть в Го можно еще круче. Собственно, мы можем застать эту эпоху, когда поединки нейронных сетей будут открывать нам новые идеи. Хотя я боюсь, что тренировка сети на базе игр с KGS наложила какую-то рамку «типовой игры человека в Го». Пока то, что мы видим в поединках AlphaGo с человеком демонстрирует изобилующую стандартами игру. Может ли программа создавать новое?

Бессмертные играют в Го. Традиционный сюжет китайских легенд о происхождении игры. Google и Facebook есть на кого равняться
Что нас ждет после поражения чемпионов? Я думаю, что разработчики из DeepMind откроют возможность всем желающим сразиться с их детищем. И миллионы безымянных гениев со всего мира бросят вызов AlphaGo. Серьезным вызовом для нейросети будет выход за рамки стандартных розыгрышей и стратегий, усвоенных при изучении KGS. Но она же самообучающаяся. Поэтому она изучит всю возможную тактику и стратегию человека и превзойдет ее. Вот тогда она станет по-настоящему непобедимой и сможет совершенствоваться в борьбе со своими конкурентами-нейросетями за звание абсолютного чемпиона. Возможно, мы увидим рождение иной игры Го, не обремененной человеческим восприятием мира. Но скорее всего, отличия в стратегии будут не существенны.
Следующий шаг — борьба против нейросети силами коллективного разума. Когда игроки сами объединяются в своего рода нейросеть-команду. Это будут эпичные сражения. И я удивлюсь, если нам удастся сохранять паритет побед и поражений с программой. Все-таки конкурировать с суперкомпьютерами в скорости обучения нереально. Разве что человечество откроет в себе какие-то экстрасенсорные способности.
Конечно, Google не остановится только на игре Го. Следующий шаг — научить нейронную сеть управлять армией в миллионы дронов или автоматизировать движение автомобилей в городе. Возможно, что у правительств появятся нейронные сети-советники. Какие решения они будут предлагать? Я бы, наверное, проголосовал за депутата-аватара. Главное, чтобы он был хорошо натренирован работать и не чудил. Все несогласные с таким виртуальным правительством могут доказать свое интеллектуальное превосходство, обыграв аватара в Го.
Еще один тест, который мне пришел в голову: поручить программе научить человека играть в Го. Интересно, какую схему тренировки и обучения она может предложить?
автор М. Емельянов.
Отчет Google о разработке AlphaGo
Comments are closed.